Towards a multi-layer architecture for multi-modal rendering of expressive actions.
Navigation
Towards a multi-layer architecture for multi-modal rendering of expressive actions.
De Poli, G. and Avanzini, F. and Rodà, A. and Mion, L. and D'Incà, and Trestino, C. and Pirrò, D. and Luciani, A. and Castagne, N.
Proc. 2nd Int. Conf. on Enactive Interfaces (ENACTIVE05), 2009
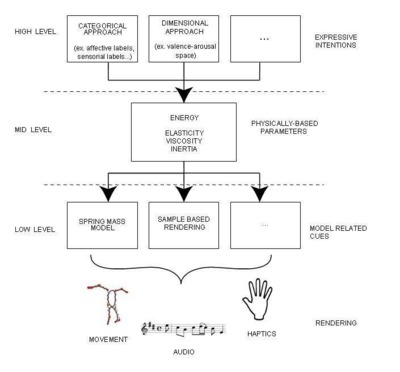
Expressive content has multiple facets that can be conveyed by music, gesture, actions. Different application scenarios can require different metaphors for expressiveness control. In order to meet the requirements for flexible representation, we propose a multi-layer architecture structured into three main levels of abstraction. At the top (user level) there is a semantic description, which is adapted to specific user requirements and conceptualization. At the other end are low-level features that describe parameters strictly related to the rendering model. In between these two extremes, we propose an intermediate layer that provides a description shared by the various high-level representations on one side, and that can be instantiated to the various low-level rendering models on the other side. In order to provide a common representation of different expressive semantics and different modalities, we propose a physically-inspired description specifically suited for expressive actions.